What is Data Mining?
- Data mining is the process of extracting the useful information, which is stored in the large database.
- Data mining is a powerful tool, which is useful for organizations to retrieve useful information from available data warehouses.
- Data mining can be applied to relational databases, object-oriented databases, data warehouses, structured-unstructured databases etc.
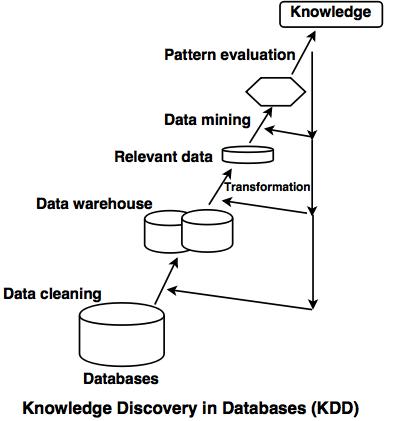
- Data mining is also called as Knowledge Discovery in Databases (KDD).
The different steps of KDD are as given below:
1. Data cleaning:
In this step, noise and irrelevant data are removed from the database.
2. Data integration:
In this step, the heterogeneous data sources are merged into a single data source.
3. Data selection:
In this step, the data which is relevant to the analysis process gets retrieved from the database.
4. Data transformation:
In this step, the selected data is transformed in such forms which are suitable for data mining.
5. Data mining:
In this step, the various techniques are applied to extract the data patterns.
6. Pattern evaluation:
In this step, the different data patterns are evaluated.
7. Knowledge representation:
This is the final step of KDD, which represents the knowledge.
Data Streams Mining
The process of obtaining the structure of knowledge or the information patterns from the existing data is called as 'Data Stream Mining'. Data stream is an ordered sequence of instances.
The techniques used to obtain stream data are as listed below:
1. Sensor data:
The sensor produces data in the stream of real numbers.
For example: Consider that the temperature sensors are set in the desert area, and hence are supposed to send the readings ( which is a stream of real numbers) of the surface temperature in each hour.
2. Image data:
Satellites send tera-bytes of image data to the earth station. The image data which is provided by surveillance cameras is of lower resolution than the satellite image.
Each type of these sources produce the streams of images in regular intervals.
3. Web traffic and Internet:
Switching node in the internet receives large streams of packets from various input sources and routes them to their desired output locations.
Switching node is used only for data transmission and not for storage.
For example: Google or yahoo accepts large amount of requests and serves thousand of queries per day.
Stream data management system
- Stream data management system is a computer program to manage continuous streams.
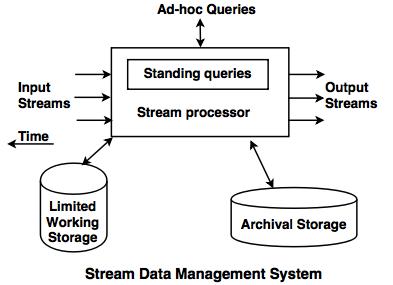
- Any number of streams can enter the system. Each stream provides elements as per its own schedule at different rate and with different data types.
- The rate of input stream elements is not controlled by the system.
- All streams can be processed in real time. So, the streams can enter into the archival storage, but it is not possible to answer the queries in archival store.
- The limited working storage is used to answer the queries. The limited working store may be disk memory or main memory which depends upon the speed required to process the queries.
Classification of stream
Stream can be classified into two steps:
1. Model construction: It refers to the construction of a model based on labeled tuples of a class extracted from an available training set.
2. Model usage: It refers to the prediction of the class of items from the new unknown sets.
- In traditional settings, the data reside in a static database and it is available for training. Multiple scans are carried out for training data . Hence, model construction phase is carried out as off-line batch process. The data-flows so quickly that the storage and scans are realistic.
- Data streams are time varying as they are opposed by the traditional database system. This feature makes the traditional database system suitable for available classification techniques as it stores only current state.
Different methods of data stream classification are given by:1. Hoeffding tree algorithm
- It is a decision tree method for data stream classification and works in sub-linear time, which produces an identical decision tree.
- The name of this algorithm is derived from hoeffding bound, which is used in tree induction.
- Hoeffiding bound gives a certain level of confidence on the best attribute to split the tree, and to construct the model based on certain number of previously seen instances.
The algorithm is basically designed to overcome the following drawbacks of existing streaming classification techniques:
1. High sensitivity to example ordering.
2. Low efficiency.
The existing techniques are slower than the batch processing. The Hoeffiding algorithm provides a better analysis in terms of quality as well as the efficiency.
Hoffiding Bound:
The Hoeffiding bound is used to decide how many examples of instances are needed to achieve certain level of confidence as:
Given:
r = real-valued random variable, with range 'R'.
n = number of independent observations
r ‾ = mean value computed from 'n' independent observations.
The Hoeffding bound implies that the probability ' 1-δ ', which is true mean of the variable is at least
r ‾ - ∈
and '∈' is derived from the formula expressed by,
∈ = √R
2 ln ( 1 / δ ) / 2n
Example: (Example of Hoeffiding bound)
Assume that the information gain difference between the two attributes (attribute A and B, information of A is greater than B) is 0.4 and ∈ = 0.1,
then, in future, the difference between A's information gain will be calculated as,
0.4 – 0.1 = 0.3
2. VFDT (Very Fast Decision Tree)
- VFDT modifies the Hoeffding tree algorithm to improve the speed and memory utilization mechanism.
- VFDT deactivates the least promising leaves at the time of low memory and drops the poor splitting attributes.
- The VFDT algorithm works great with stream data, but is unable to handle drift in data streams.
- The concept of sliding window is used to solve the drift problem. In this concept, the newly arrived examples can be inserted at the end of the window, which helps to use new examples and eliminate the effects of old examples.
- This technique is dependent on window size, 'w'. If w is small, it is not possible to store enough examples to construct an accurate model and if 'w' is too large, then the model cannot represent the concept accurately and it becomes very difficult to construct a new classifier model continuously.
- VFDT algorithm is modified in CVFDT ( Concept-Adapting Very Fast Decision Tree) to solve the concept of drifting data streams.
- CVFDT uses sliding window approach, but does not construct a new model each time from the beginning.
- CVFDT can update statistics at the node by incrementing the counts associated with new examples and decrementing the counts associated with older examples.
- CVFDT achieves better accuracy than VFDT in terms of dynamic streams and its tree size is also smaller than VFDT.
3. Classifier ensemble approach
- This approach is used to classify the concept of drifting data streams.
- In this method, group of classifiers uses strings from sequential chunks of the data stream. Therefore, when a new chunk arrives, a new classifier is built from it.
- Individual classifier are weighted based on their expected classification accuracy in dynamic environment. The decisions are taken on the basis of weighted votes of classifiers.



