Introduction to Text Classification
The text classification is the process of assigning predefined categories to the text documents.
For example: Classification of e-mail messages as spam and non-spam.
Text classification can be categorized as:1. Content based classification
In this type, the weight is assigned to particular topic in the document which determines the class to which the document is assigned.
For example:
A common rule can be followed by libraries that at least 30% of the book should be about the class which the subject is assigned.
2. Request based classification
In this classification, the expected request from users can be considered, while classifying the documents.
For Example:
Library or database for a particular subject, e.g. technical studies can classify the documents differently by comparing with historical data.
Recommendation System and Collaborative Filtering:
The recommendation system is used in many applications which works on predicting the users interest.
For Example:
In an e-commerce website, after adding some items to the shopping cart, some suggestions are provided to the user.
The recommendation system uses the number of different techniques, which can be divided as:1. Content based system
Content based systems examine the properties of the recommended items.
For example:
In youtube, the content based system works on the basis of previous search (videos or movies). The system can filter the recent and most popular videos or movies, which can be searched by many users.
In content based system, it is necessary to construct a profile. A profile is a record or collection of records, which provides some important characteristics of an item.
Some preferences of users to construct simple profile about the song recommendation system are List of singers, actors in the song, type of song, etc.2. Collaborative filtering systems
Collaborative filtering is a method of making automatic filtering of the user's interest by collecting references from many users.
Collaborative filtering systems recommend the items on the basis of similarity measures between users and items. Items are recommended by the systems to new users, which are mostly preferred by other users.
Text Categorization Methods:
The three important and most commonly used categorization methods are:1. Decision tree
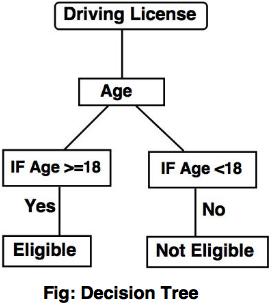
- A decision tree performs the classification in the form of tree structure. It breaks down the dataset into small subset and a decision tree can be designed simultaneously.
- The final result is a tree with decision node.
For example:
The following decision tree can be designed to declare a result whether an applicant is eligible or not eligible to get the driving license.
2. K-Nearest Neighbour Classification:
- If an user wants to build the system, then the objects are classified into specific classes.
For example: Each object may be the image of dog, and classification may include recognizing the breed of dog. - K-Nearest Neighbour classification can be very useful in document classification.
- K-nearest Neighbour algorithm classifies a new object by comparing it to all previously seen objects or documents. The classification of the most similar previous objects or documents can be used to predict the classification of current query (object or object).
To classify a new document, necessary steps are:
1. Compute similarity of documents or objects, with all available documents.
2. Select K-nearest Neighbours.
3. Combine the previous classifications to a new prediction.
Example:
The Collaborative filtering can be done using K- Nearest Neighbour algorithm
Collaborative filtering attempts to predict the opinion of the user about the different items and can be able to recommend the best items to each user, which is based on previous preference and opinion of the other users.
The task of collaborative filtering is to find likeliness of items in two ways:
1. Prediction
A numeric value, which represents the predicted like value about an item of the active user.
2. Recommendation
The list of items which is most liked by an active user.
Applying K- Nearest Neighbour Algorithm- This is very useful algorithm to find nearest items among the whole collection, so it can be used in collaborative filtering.
- The most important point in this algorithm is, a term similarity.
- To recommend something to the user by asking question, the user can find people from his neighborhood, which are having similar profiles.
- To recommend something to the user in question, the user can find people from his neighborhood having similar profile.
3. Naive Bayes Classification
- Naive Bayes classification is a technique based on Bayes theorem.
- Naive Bayes model is easy to implement and very useful for large dataset.
- Naive Bayes is a conditional probability model, as:
P (c ∣ x) = P (c ∣ x) P (c) / P (x)
Where,
P (c ∣ x) is the posterior of probability.
P (c) is the prior probability.
P (c ∣ x) is the likelihood.
P (x) is the prior probability.
Matrix Factorization:
- Matrix Factorization is a simple mathematical tool which works on matrices and used to find the hidden data.
- Most of the MF models are based on latent factor model. The latent factor model cannot calculate the similarities to predict ratings like neighborhood method.
- Latent factor methods can guide a model on some known data by extracting U users and items latent factors and predict ratings by multiplying user factors with item factors.
- Consider a set of users 'U' and a set of items I. Let R be the matrix size.
∣ U∣ * ∣ I ∣ consists of ratings which users have assigned to the items.
It is necessary to find two matrices
P (∣U∣ * K) and Q( ∣ I ∣ * k), the product of these matrices can be expressed as:
R = ≈ P * QT = R
Matrix Factorization model can map the users and items to join latent factor space of dimension f.



