Data Replication in Distributed System
What is data replication?
Data replication is the process in which the data is copied at multiple locations (Different computers or servers) to improve the availability of data.
Goals of data replication
Data replication is done with an aim to:- Increase the availability of data.
- Speed up the query evaluation.
Types of data replication
There are two types of data replication:
1. Synchronous Replication:
In synchronous replication, the replica will be modified immediately after some changes are made in the relation table. So there is no difference between original data and replica.
2. Asynchronous replication:
In asynchronous replication, the replica will be modified after commit is fired on to the database.
Replication Schemes
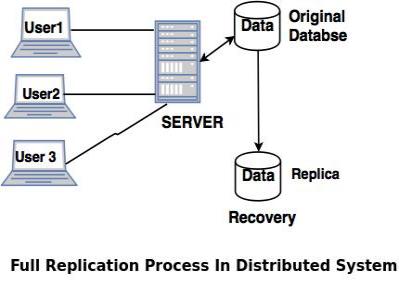
The three replication schemes are as follows:1. Full Replication
In full replication scheme, the database is available to almost every location or user in communication network.
 Advantages of full replication
Advantages of full replication- High availability of data, as database is available to almost every location.
- Faster execution of queries.
Disadvantages of full replication- Concurrency control is difficult to achieve in full replication.
- Update operation is slower.
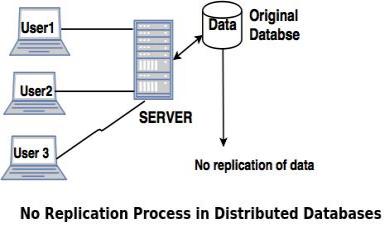
2. No Replication
No replication means, each fragment is stored exactly at one location.
 Advantages of no replication
Advantages of no replication- Concurrency can be minimized.
- Easy recovery of data.
Disadvantages of no replication- Poor availability of data.
- Slows down the query execution process, as multiple clients are accessing the same server.
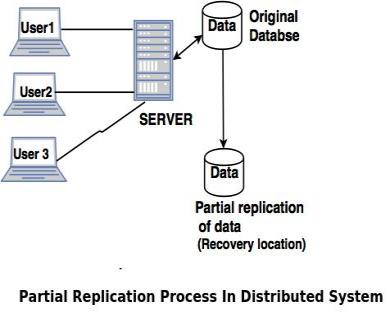
3. Partial replication
Partial replication means only some fragments are replicated from the database.
 Advantages of partial replication
Advantages of partial replication
The number of replicas created for fragments depend upon the importance of data in that fragment.
Distributed databases - Query processing and Optimization
DDBMS processes and optimizes a query in terms of communication cost of processing a distributed query and other parameters.
Various factors which are considered while processing a query are as follows:Costs of Data transfer
- This is a very important factor while processing queries. The intermediate data is transferred to other location for data processing and the final result will be sent to the location where the actual query is processing.
- The cost of data increases if the locations are connected via high performance communicating channel.
- The DDBMS query optimization algorithms are used to minimize the cost of data transfer.
Semi-join based query optimization
- Semi-join is used to reduce the number of relations in a table before transferring it to another location.
- Only joining columns are transferred in this method.
- This method reduces the cost of data transfer.
Cost based query optimization
- Query optimization involves many operations like, selection, projection, aggregation.
- Cost of communication is considered in query optimization.
- In centralized database system, the information of relations at remote location is obtained from the server system catalogs.
- The data (query) which is manipulated at local location is considered as a sub query to other global locations. This process estimates the total cost which is needed to compute the intermediate relations.
Distributed Transactions
- A Distributed Databases Management System should be able to survive in a system failure without losing any data in the database.
- This property is provided in transaction processing.
- The local transaction works only on own location(Local Location) where it is considered as a global transaction for other locations.
- Transactions are assigned to transaction monitor which works as a supervisor.
- A distributed transaction process is designed to distribute data over many locations and transactions are carried out successfully or terminated successfully.
- Transaction Processing is very useful for concurrent execution and recovery of data.



