Object Based Databases Tutorial
Object oriented database systems carry information in the form of objects.
Object Based Databases Tutorial
Learn the concepts of Object Based Databases with this easy and complete Object Based Databases Tutorial. This tutorial discusses the concept, models, features of Object Oriented databases with examples. Beginners, freshers, BE, BTech, MCA, college students will find it useful to develop notes, for exam preparation, solve lab questions, assignments and viva questions. Who is this Object Based Databases Tutorial designed for?
This tutorial is specially designed for beginners who want to learn, practice and improve their Database Management skills. What do I need to know to begin with?
Object Based Databases is a sub-system of DBMS. A good knowledge of DBMS is very important to start learning this topic. Object Based Databases syllabus covered in this tutorial
This tutorial covers, Features of OODBMS, Object and Attributes, Structured & Unstructured Data, Storage Methods in DBMS, challenges etc.
Introduction to Object based databases
- Object oriented database systems are alternative to relational database and other database systems.
- In object oriented database, information is represented in the form of objects.
- Object oriented databases are exactly same as object oriented programming languages. If we can combine the features of relational model (transaction, concurrency, recovery) to object oriented databases, the resultant model is called as object oriented database model.
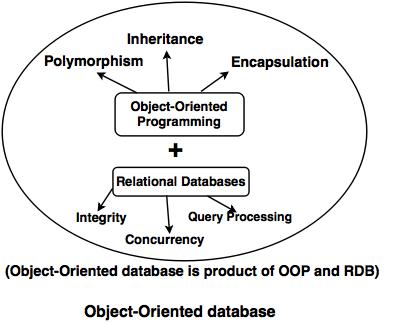
Features of OODBMS
In OODBMS, every entity is considered as object and represented in a table. Similar objects are classified to classes and subclasses and relationship between two object is maintained using concept of inverse reference.
Some of the features of OODBMS are as follows:
1. Complexity
OODBMS has the ability to represent the complex internal structure (of object) with multilevel complexity.
2. Inheritance
Creating a new object from an existing object in such a way that new object inherits all characteristics of an existing object.
3. Encapsulation
It is an data hiding concept in OOPL which binds the data and functions together which can manipulate data and not visible to outside world.
4. Persistency
OODBMS allows to create persistent object (Object remains in memory even after execution). This feature can automatically solve the problem of recovery and concurrency.
Challenges in ORDBMS implementation
During the implementation of ORDBMS, various challenges arise which need to be resolved. They are:
1. Storage and accessibility of data
It is possible to define new types with new access to structures with the help of OODBMS. Hence, it is important that the system must store ADT and structured objects efficiently along with the provision of indexed access.
Challenge : Storage of large ADTs and structured objects.
Solution: As large ADTs need special storage, it is possible to store them on different locations on the disk from the tuples that contain them.
For e.g. BLOBs (Binary Large Object like images, audio or any multimedia object.)
Use of flexible disk layout mechanisms can solve the storage problem of structured objects.
2. Query Processing
Challenge: Efficient flow of Query Processing and optimization is a difficult task.
Solution: By registering the user defined aggregation function, query processing becomes easier. It requires three implementation steps -
initialize, iterate and terminate.
3. Query Optimization
Challenge: New indexes and query processing techniques increase the options for query optimization. But, the challenge is that the optimizer must know to handle and use the query processing functionality properly.
Solution: While constructing a query plan, an optimizer must be familiar to the newly added index structures.
For a given index structure, the optimizer must know:
1. WHERE-clause conditions matched by that index.
2. Cost of fetching a tuple for that index.



